Face Detection
In this post I will describe how I built a face detector using the WIDER Face dataset.
Initially I had planned to implement Faster RCNN architecture from scratch. Even though the anchor generation and bounding box regression seemed conceptually easy, the actual implementation turned out to be complex, where I wasn’t sure whether I was computing the gradient flow correctly. So I have paused on that for now, and went ahead with training the faster RCNN model architecture API provided in pytorch. Even in this case, a batch size of just 4 takes almost 9GB of VRAM, so has to be taken into account before implementing.
Data
In this project, I have used the WIDER dataset which has around 12880 training images. The dataset also provides the target boxes in the following format:
File Name
No of faces
x1, y1, w, h, blur, expression, illumination, invalid, occlusion, pose39--Ice_Skating/39_Ice_Skating_Ice_Skating_39_370.jpg
5
333 310 102 130 1 0 0 0 0 0
454 296 73 120 1 0 0 0 0 0
708 430 34 55 1 0 0 0 0 0
736 410 35 41 1 0 0 0 0 0
759 529 39 56 1 0 0 0 0 0 For each face, I have used only x1, y1, w, h. Some things to keep in mind while loading the data:
- When there are no faces in the image, the data file still has an extra line with all values 0. So it has to be ignored.
- Some boxes have 0 width or 0 height. So have to be ignored.
- Depending on resizing of image, the bounding boxes also get resized. After resizing it might happen that, because integer rounding, the width or height becomes 0, so its better to ignore these images as well. In my case, I have just set a area threshold so that resizing any box bigger than that usually wouldnt cause width or height to vanish.
Some sample images

Model and Training
As mentioned before, I used the Faster RCNN architecture API provided by pytorch and made a few changes to it. I replaced the Resnet50 backbone with a MobileNetv2 backbone, pretrained on ImageNet and modified the no of classes to 2, since I’m only detecting faces (background is +1)
backbone = torchvision.models.mobilenet.mobilenet_v2(pretrained=True).features
backbone.out_channels = 1280
anchor_generator = AnchorGenerator(sizes=((32, 64, 128, 256, 512),),
aspect_ratios=((0.5, 1.0, 2.0),))
roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=['0'],
output_size=7,
sampling_ratio=2)
model = FasterRCNN(backbone,
num_classes=2,
rpn_anchor_generator=anchor_generator,
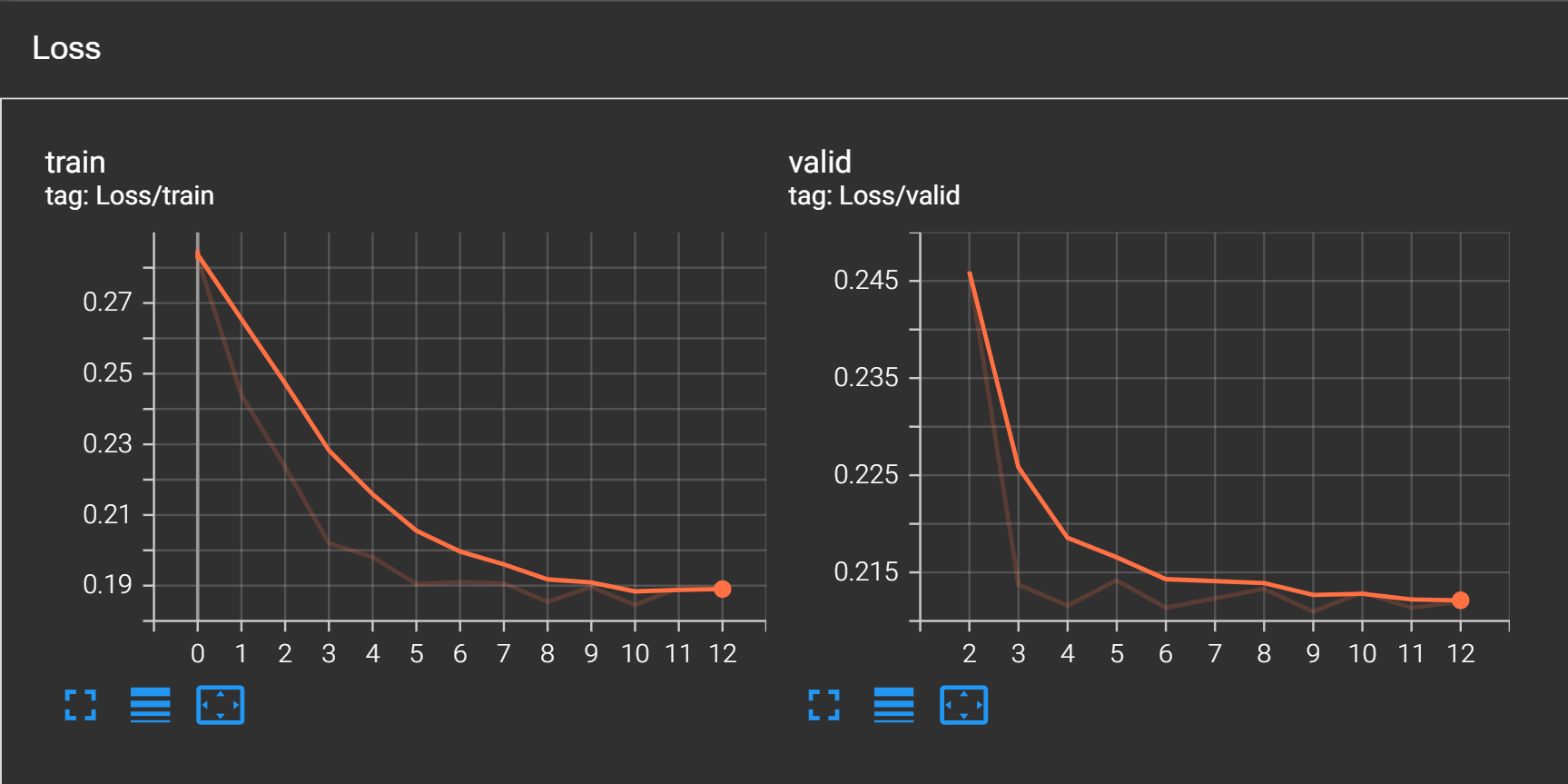
box_roi_pool=roi_pooler)I trained the model with SGD optimizer and a step learning rate scheduler for just 12 epochs, when I noticed that loss started to increase a bit. Upon manually checking, I was quite surprised to see that model has already learnt to detect faces pretty well in just 12 epochs.
Loss curves
Testing
I tested the model qualitatively on a few personal images as well as images obtained from Pexels, to see whether model is working as I expected. And it seems to be performing pretty well. There were some false positives and overlapping detections, so I added a score threshold of 0.8 to filter the boxes which are not confident. And also applied Non-maximum suppression on all the filtered boxes with an IOU threshold of 0.5. And this removed all the extra boxes (atleast for the images I tested).



Photo by fauxels from Pexels
Photo by Athena from Pexels
Conclusion
By relying on the pytorch API it becomes quite easy to train an object detection model. But the hardware requirements seem significant. The only way I was able to get this running is because of the free preview of AWS SageMaker Studio Lab, as training needs a lot of GPU memory even for small batch size. (I tried Google colab as well, but some of the restrictions make it really hard to actually complete training…maybe another post someday) But coming to the object detection itself, its amazing that a face detection model could be trained with just 12 epochs. (Using a model pretrained on ImageNet ofcourse). In this project I mostly did a qualitative evaluation, but it would be nice to do a proper quantitative evaluation, maybe in a competition setting.