Reverse Image Search
Wikipedia says
Reverse image search is a content-based image retrieval (CBIR) query technique that involves providing the CBIR system with a sample image that it will then base its search upon; in terms of information retrieval, the sample image is what formulates a search query.
In this post, I will describe how I built a reverse image search using deep learning.
The idea is to use the output from one of the layers of a pre-trained model to get embeddings (a vector representation) for each image and then use Cosine similarity between the query image and other images to get the closest image. Since the model has learnt to classify the images, assumption here is that, the model achieves this by mapping image to a representation such that image with similar content produce similar representation. The dataset I have used in this project is the Intel Image Classification dataset from kaggle.
I will do this in 2 ways:
- Directly using pre-trained model.
- Finetune the pre-trained model and then get a weighted output.
Directly using pre-trained model
In this case, I will use the Resnet50 model trained on ImageNet, remove the last classification layer and use the output from the average pooling layer to get embeddings of length 2048 for each image.
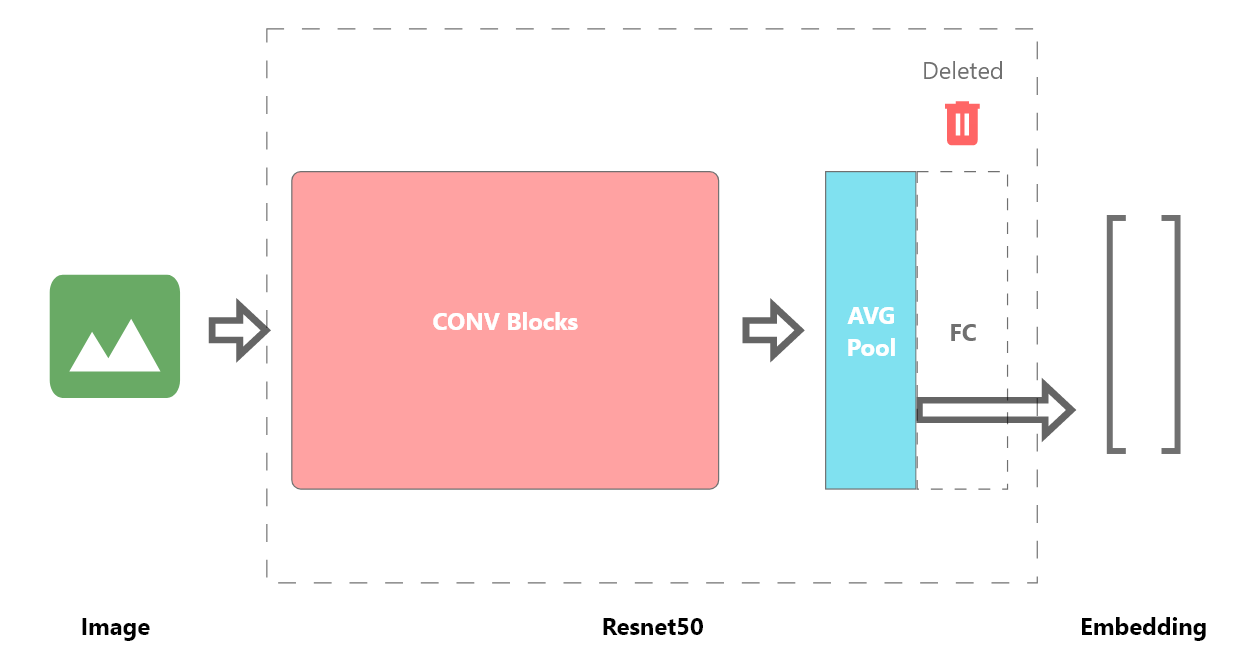
I implemented the following class to remove the last layer
class Intermediate(nn.Module):
def __init__(self, original_model):
super().__init__()
self.features = nn.Sequential(*list(original_model.children())[:-1])
def forward(self, x):
x = self.features(x)
return xI ran this for test images and saved their embeddings in a pickle file. And to see whether it works I googled for some similar images and used them as query samples.
To measure how close the embeddings are, I used the CosineSimilarity function. Cosine Similarity uses orientation to measure closeness in contrast to Euclidean distance which measures vector distance. This is supposed to be better in this context because we are measuring how similar to images are, so an image vector with more of same content could be having same orientation but much higher amplitude. The cosine similarity is bounded in the range [-1, 1]. The vectors having same orientation will have cosine similarity as 1. The vectors which are orthogonal will have close to 0 and vectors which are in opposite direction will have -1. So to get a measure of distance, we use Cosine Distance = 1 - Cosine Similarity. Now smaller the distance, closer the images are.
cos = nn.CosineSimilarity(dim=0)
cosine_distance = 1 - cos(query_image_feature, image_feature)Results
Good
 Kinda good
Kinda good
 Bad
Bad


So some results are pretty decent, but its not able to properly associate similar images in many instances. So onto the next approach.
Finetuning the model
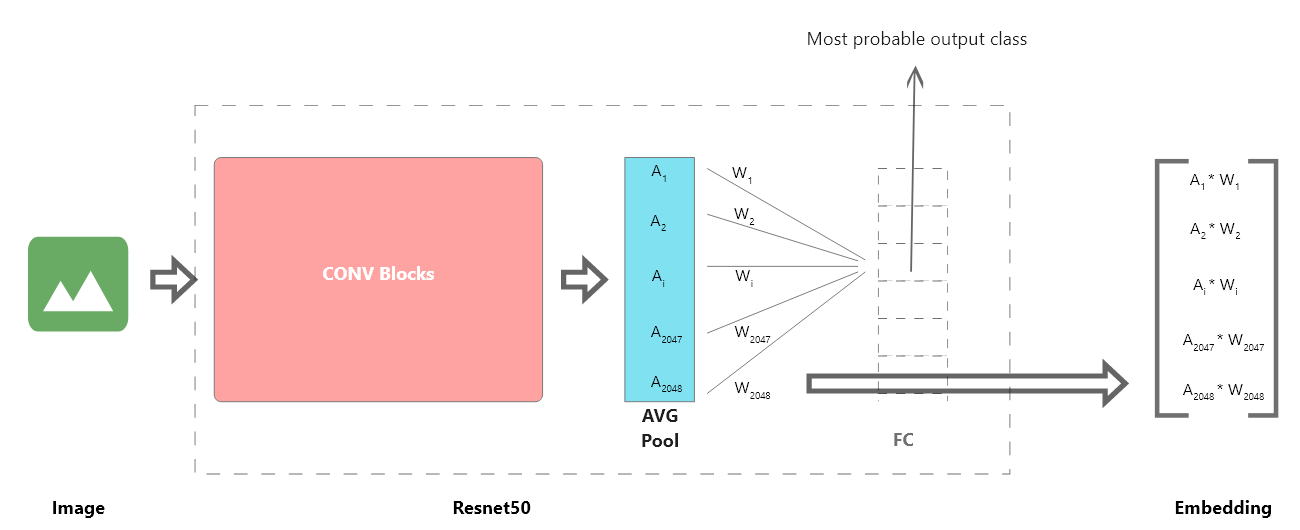
In this case, I will take the pre-trained Resnet50 model, replace the last layer with new fully connected layer having 6 outputs as this dataset has 6 classes and train it. Once its trained to sufficiently high accuracy, I will use the output from the average pooling layer and multiply with the weights associated with the most probable class of the image.
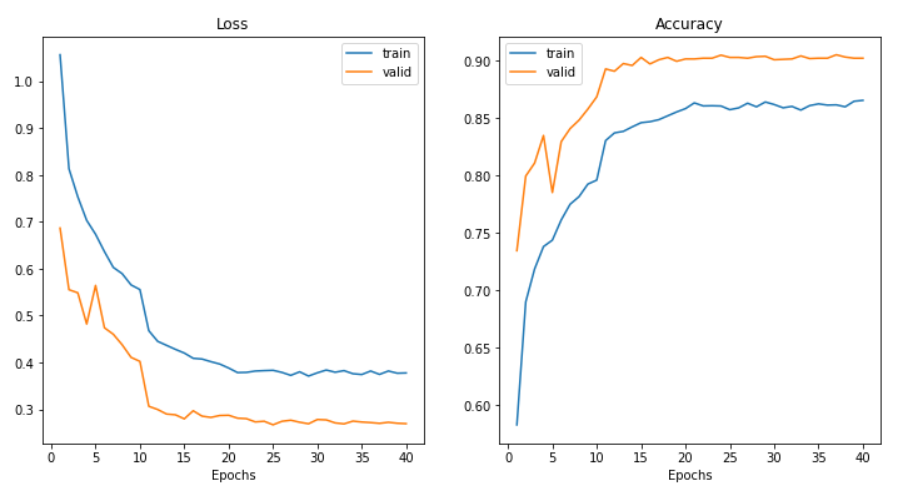
I fine tuned the model for around 40 epochs (after a bit of experimenting with learning rates and decay rate) and got a validation accuracy of about 90%. From the learning curves, it can be seen that the model is saturating even though validation accuarcy is higher than training accuracy. Maybe using a bigger model or tuning the hyperparameters bit more I could have got a better accuracy, but I think this is ok for my purpose.
I modified the previous Intermediate class to multiply the weights like below.
class WeightedIntermediate(nn.Module):
def __init__(self, original_model):
super().__init__()
self.features = nn.Sequential(*list(original_model.children())[:-1])
self.classifier = list(original_model.children())[-1]
def forward(self, x):
x = torch.squeeze(self.features(x))
outputs = self.classifier(x)
_, class_indices = torch.max(outputs, -1)
weights = self.classifier.weight
if len(x.shape) > 1:
for i in range(len(class_indices)):
x[i] = x[i] * weights[class_indices[i]]
else:
x = x * weights
return xResults
Good is still good

Others much better



Conclusion
In conclusion, we can search for image by content by using models trained for classification and using an embedding vector from it. Even though the pre-trained model is pretty bad, by conditioning the embeddings over the most probable output class obtained after fine tuning the model for classification, results are much better.